Why thermal reliability now defines AI data center ROI.
—
The economics of AI infrastructure have changed. GPUs are no longer short-cycle compute assets optimized purely for peak performance; they are multi-year balance-sheet investments whose value must be preserved under extreme thermal and mechanical stress. For data center operators and tenants alike, the question is no longer how fast GPUs can run on day one, but how well they retain performance, efficiency, and economic value over six years or more.
At the center of this challenge sits an often overlooked component: the thermal interface material (TIM). Existing TIMs such as phase-change materials (PCMs) were never designed for today’s AI duty cycles. As GPU power densities and sustained workloads climb, these materials introduce hidden failure mechanisms that quietly increase thermal resistance and erode asset value: voiding, pump-out and dry-out.
In an era where GPU depreciation drives CapEx decisions and energy efficiency defines OpEx outcomes, re-pasting thermal interfaces is no longer acceptable. The industry is entering what many now describe as a “value cascade” — where protecting hardware reliability directly preserves ROI, balance-sheet strength, and competitive advantage, and where forward-looking operators are already working with Carbice to eliminate these wasteful losses through system-level thermal reliability at scale; read how DarkNX and Carbice are partnering across 300 MW of AI data centers to set this new standard in cooling reliability
The Hidden Cost of Thermal Degradation
Modern AI GPUs operate at sustained power levels that expose the limitations of legacy TIMs. Legacy TIMs are prone to:
- Pump-out under thermal cycling
- Performance drift over time
- Increased junction temperatures
- Extreme temperature gradients & hotspots
- Higher failure and rework rates
- Reduced energy efficiency per workload
Each of these problems contributes to accelerated GPU degradation. The result is not always an immediate failure, but is costly nonetheless: gradual loss of performance efficiency, rising power consumption, increased rework, and shortened useful life.
Recent modeling shows that thermally degraded GPUs can consume an additional 294 kWh over five years, even when they remain operational. When scaled across modern AI fleets, the impact becomes enormous.
A Global Perspective: Energy Waste at AI Scale
Today, the global installed base of data center GPUs is estimated at approximately 7 million units and growing rapidly. If thermal degradation causes even modest efficiency losses across this population, the cumulative energy and emissions impact is staggering.
That’s over 2 Terawatt Hours of electricity consumed with no increase in computational output — pure inefficiency driven by thermal performance loss.
At an average grid carbon intensity of 350 g CO₂ per kWh, this wasted energy corresponds to: ~721,000 metric tons of avoidable CO₂ emissions.
This is the equivalent of the annual electricity emissions of a mid-sized city, created not by new compute demand, but by degraded thermal interfaces quietly undermining GPU efficiency.
This is the equivalent of the annual electricity emissions of a mid-sized city, created not by new compute demand, but by degraded thermal interfaces quietly undermining GPU efficiency.
For operators tracking Scope 2 emissions and tenants scrutinizing sustainability commitments, this wasted energy is increasingly difficult to justify.
The Facility-Level View: A 300 MW AI Data Center
Zooming in from the global scale, the economics remain just as compelling — if not more so. Consider a 300 MW AI data center operating approximately 100,000 GPUs. Using the same conservative degradation assumptions:
- Additional energy per GPU (5 years): 294 kWh
- Total wasted energy (5 years): 29.4 GWh
That equates to:
- Enough electricity to power ~2,800 U.S. homes for a year
- ~10,300 metric tons of avoidable CO₂
- ~$2.9 million in wasted electricity (at $0.10/kWh)
See the Press Release: "Carbice and DarkNX Partner to Advance Reliability and Performance Across over 300MW of AI Data Centers"
Depreciation Economics and the “Value Cascade”
The value cascade concept highlights how early design and component decisions compound over time, either preserving or destroying economic value across an asset’s lifecycle. In AI data centers, thermal reliability sits squarely at the top of that cascade.
As highlighted in recent industry analysis, GPU assets increasingly need to deliver six years or more of productive life to meet modern ROI expectations. Every efficiency loss accelerates depreciation, compresses usable life, and forces earlier capital refresh.
PCM pump-out and re-work cycles directly violate this model. Rework is disruptive, labor-intensive, and increasingly incompatible with large-scale AI operations. More critically, it introduces variability — exactly what hyperscalers and colocation tenants are trying to eliminate. Pump-out and re-work are unacceptable in the new GPU depreciation economics.
OEMs and end users adopting Carbice Pad as their critical thermal interface are already demonstrating the ability to exceed the traditional six-year value cascade. By eliminating thermal degradation as a failure mode, they are stabilizing performance, energy efficiency, and predictability, turning GPUs back into long-life economic assets rather than fragile consumables.
Why Carbice Changes the Thermal Equation
Carbice Pad was engineered specifically to address the failure mechanisms inherent in legacy TIMs. Carbice delivers:
- No pump-out or dry-out
- Thermally stable performance over time
- Predictable behavior under sustained AI workloads
- No need for re-pasting or rework
- Lower junction temperature drift
- Consistent energy efficiency across life
For operators, this translates directly into lower OpEx: fewer interventions, less downtime, reduced labor, and lower energy waste. For tenants, it protects CapEx by extending usable GPU life and preserving depreciation schedules.
Importantly, Carbice’s stability enables system-level predictability, a prerequisite for scaling AI infrastructure without compounding operational risk.
When thermal behavior is predictable, distributed training runs keep from throttling, utilization remains high, and the feedback loop between software scaling and hardware performance accelerates.
When thermal behavior is predictable, distributed training runs keep from throttling, utilization remains high, and the feedback loop between software scaling and hardware performance accelerates.
As described in “Characterizing the Efficiency of Distributed Training: A Power, Performance, and Thermal Perspective”, thermal dynamics directly shape power efficiency, throughput, and overall training efficiency—making stable thermal interfaces a quiet but critical lever for maximizing the economic value of AI hardware.
The TCO Advantage No One Can Ignore
When viewed through a Total Cost of Ownership (TCO) lens, the thermal interface is no longer a minor line item. It is a leverage point. By preventing degradation instead of reacting to it, Carbice helps data centers:
- Reduce energy waste and Scope 2 emissions
- Avoid costly GPU rework and maintenance cycles
- Minimize downtime and operational disruption
- Extend the economic lifetime of GPU assets
- Improve balance-sheet efficiency and ROI
In a world where AI infrastructure is capital-intensive, energy-constrained, and scrutiny-heavy, these advantages compound — just like the value cascade itself.
Protect the GPU, Protect the Business
As AI data centers scale in power density, cost, and strategic importance, preserving the economic lifetime of GPU assets is no longer optional—it is fundamental to protecting ROI. Thermal degradation from legacy interface materials quietly undermines performance, inflates energy consumption, accelerates depreciation, and introduces operational risk that compounds over time. By eliminating known failure mechanisms and stabilizing thermal performance over the full life of the system, operators and tenants can extend asset value, reduce OpEx volatility, and align infrastructure strategy with long-term business outcomes.
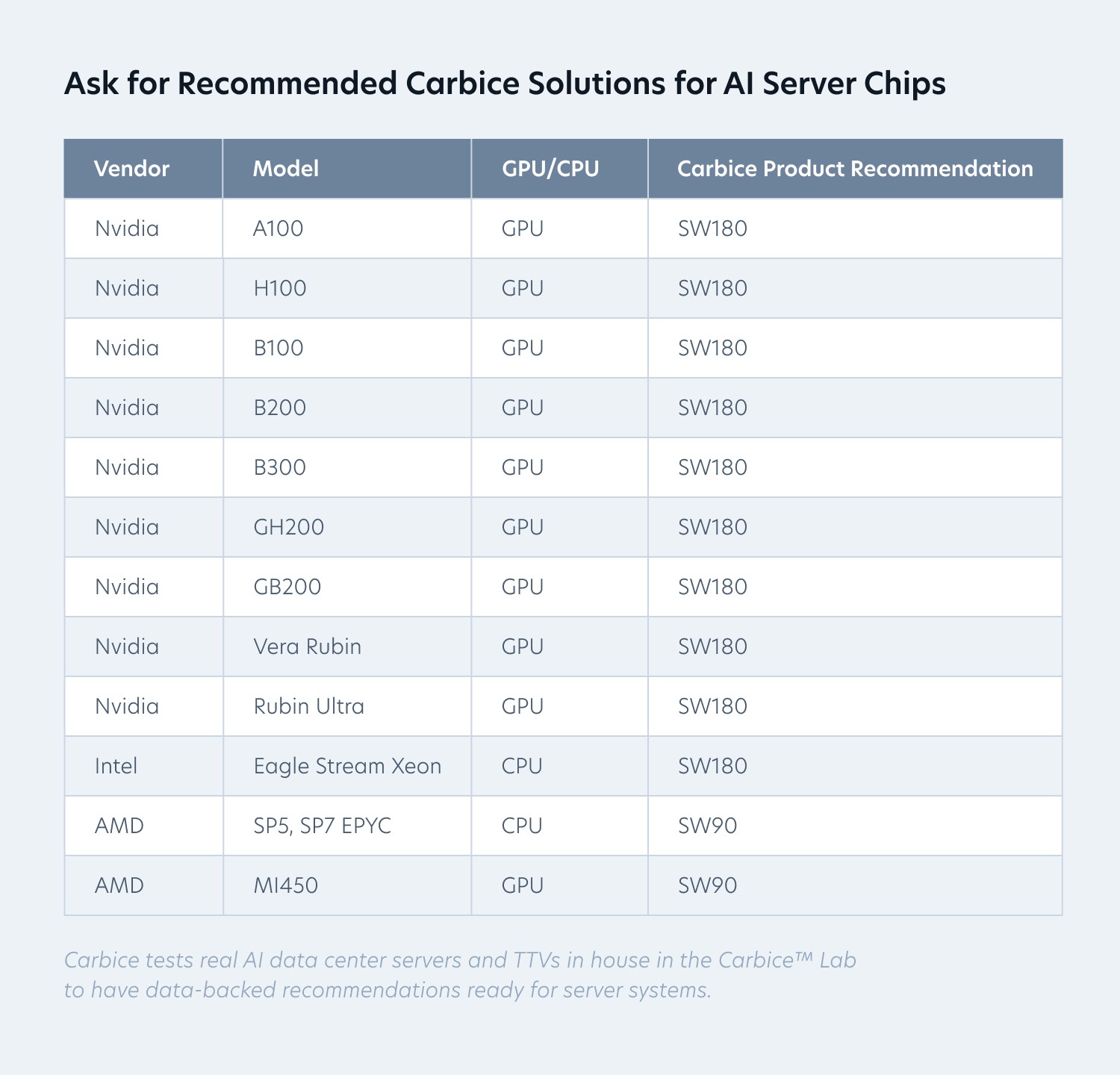
For organizations designing, operating, or capitalizing AI data center infrastructure, thermal interfaces should be treated as an economic variable—not a commodity. Carbice has validated thermal performance across leading AI CPU and GPU platforms using real application testing, enabling clear, data-driven material selection. The recommendations below map Carbice solutions to common AI server chips:
Get in touch with Carbice to learn how leading operators and OEMs are working with our team to reduce rework, cut energy waste, and protect GPU performance and economic value across the life of their data centers.
